flowchart LR
DataIngestion ==> Embeddings
DataIngestion ==> CommentModeration
Embeddings ==> TopicModeling
TopicModeling ==> Labeling
TopicModeling ==> Structure
CommentModeration ==> TopicModeling
Structure & Labeling ==> Tree
Tree == Agreement Scoring ==> Insights
DataIngestion[Data Ingestion]
CommentModeration[Comment \n Moderation]
Labeling[Topic Label \n Generation]
TopicModeling[Topic Modeling]
Structure[Insight \n Generation]
Tree[Argument Mapping]
Insights[Actionable Insights]
Advancing Policy Insights
Opinion Data Analysis and Discourse Structuring Using LLMs
2024-04-03
Background
- Issue Based Information System (IBIS) (1970)
- gIBIS (1988)
- Compendium (2001)
- Deliberatorium(2008)
- DebateGraph (2008)
- Polis (2016)
- Kialo (2017)
- Large Language Models
- Summarization, information extraction - derive insights
- Classification - content moderation
- Model semantic relationships - measure support
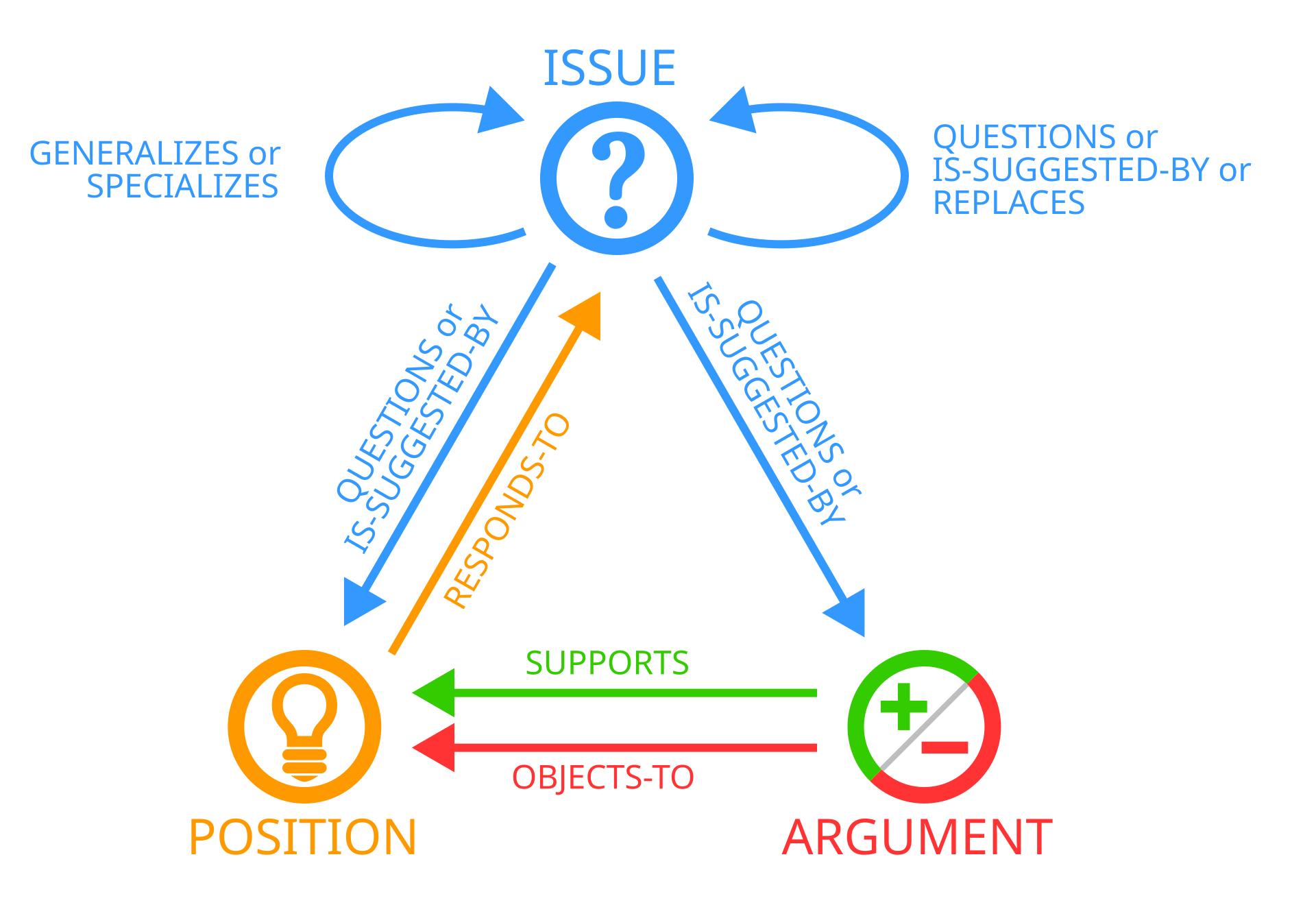
gIBIS
- Networked decision support system (J. Conklin and Begeman 1988)
- Structured conversation using
- Issues
- Positions
- Arguments
- Helped identify underlying assumptions
- Promoted divergent and convergent thinking
- Limited by structure, learning curve, scalability
- Led to development of Compendium
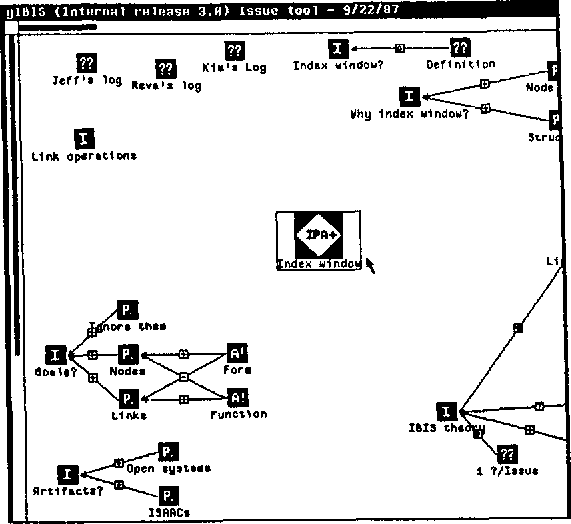
Polis
- “Real-time system for gathering, analyzing and understanding” public opinion (Small 2021)
- Developed as an open source platform for public discourse
- Published several case studies
- Participants post short messages and vote on others
- Polis algorithm ensures exposure to diverse opinions
- \(\vec{comments} \times \vec{votes} =\) opinion matrix
- fed into statistical models
- understand where people agree or disagree
Crowd-Scale Deliberation for Complex Problems
- Deliberatorium (Klein 2022)
- Knowledge Schema: QuAACR
- Questions
- Answers
- Arguments (+, -)
- Criteria
- Ratings
- Decision: Group Consensus
- Attention Mediation determines next deliberation actions
- Ideation: Generate more answers
- Assessment: Evaluate answers
- Selection: Pick best answers
- Metrics: Support, Pareto-optimality, Controversiality, Maturity, Decision confidence, Value of information, User Expertise

Embeddings
- Numerical vectors; semantical meaning of a word or sentence
- Transformer embeddings are contextually relevant; used in LLM inference
- e.g. “bank” could be a financial institution or a river side
- Calculated at comment level using Sentence Transformers library
- Models considered
- intfloat/e5-mistral-7b-instruct
- WhereIsAI/UAE-Large-V1
- OpenAI/text-embedding-ada-002
- OpenAI/text-embedding-3-large
- Language Model Selection Criteria
- Open weights
- Clustering performance on HuggingFace MTEB
- Memory footprint

Text Generation
- Models Considered
- Guidance
- Python-based framework developed by Microsoft Research
- Constrain generation using regular expressions, context-free grammars
- Interleave control and generation seamlessly
lm += f"""\
The following is a character profile for an RPG game in JSON format.
```json
{{
"id": "{id}",
"description": "{description}",
"name": "{gen('name', stop='"')}",
"age": {gen('age', regex='[0-9]+', stop=',')},
"armor": "{select(options=['leather', 'chainmail', 'plate'], name='armor')}",
"weapon": "{select(options=valid_weapons, name='weapon')}",
"class": "{gen('class', stop='"')}",
"mantra": "{gen('mantra', stop='"')}",
"strength": {gen('strength', regex='[0-9]+', stop=',')},
"items": ["{gen('item', list_append=True, stop='"')}", "{gen('item', list_append=True, stop='"')}", "{gen('item', list_append=True, stop='"')}"]
}}```"""
Output: Three-Class Classification

Use of Examples
Second-Thought Technique

- False Positives cause more harm
- Allow the model to turn a REJECT into UNSURE
Output: Comment Deconstruction and Thought Statements

Comment Moderation
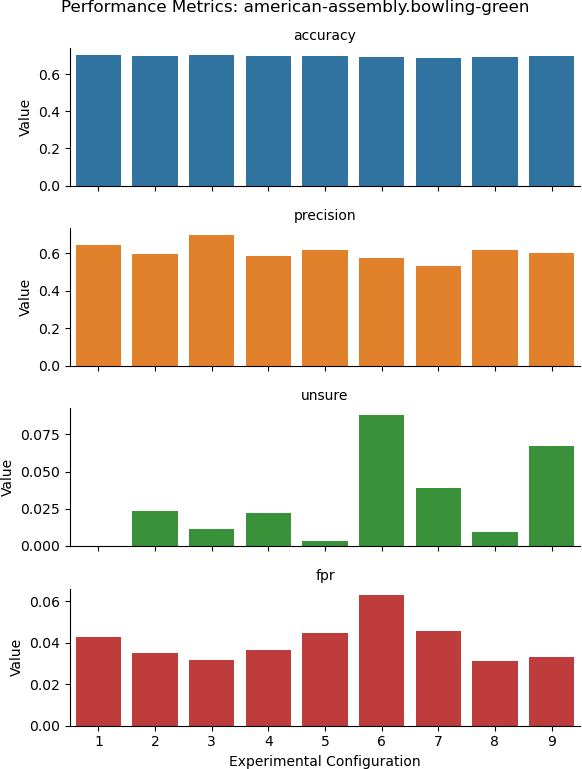
- Accuracy generally the same
- Unsure rate increases with complexity of task
- Deconstruction reduces false positive rate
- CoT not as effective as deconstruction
- Examples must be specific to dataset
Configurations
- 1: Baseline
- 2: Examples
- 3: Thought
- 4: Thought + Examples
- 5: 7-class Baseline
- 6: Thought
- 7: Thought + Deconstruction
- 8: Deconstruction
- 9: Deconstruction, 3-class

UMAP 2D Projection of Reduced Embeddings
Final parameters:
n_neighbors = 8min_dist = 0n_components = 32metric = 'cosine'
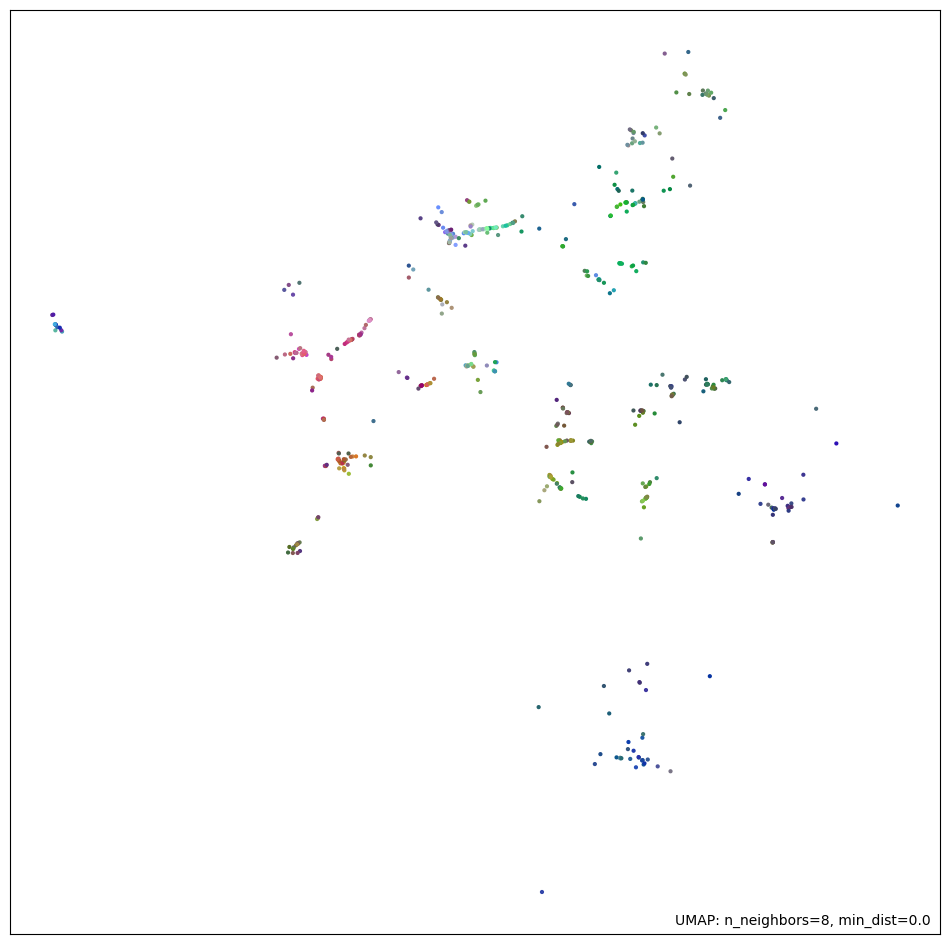
american-assembly.bowling-green dataset
Topic Distribution
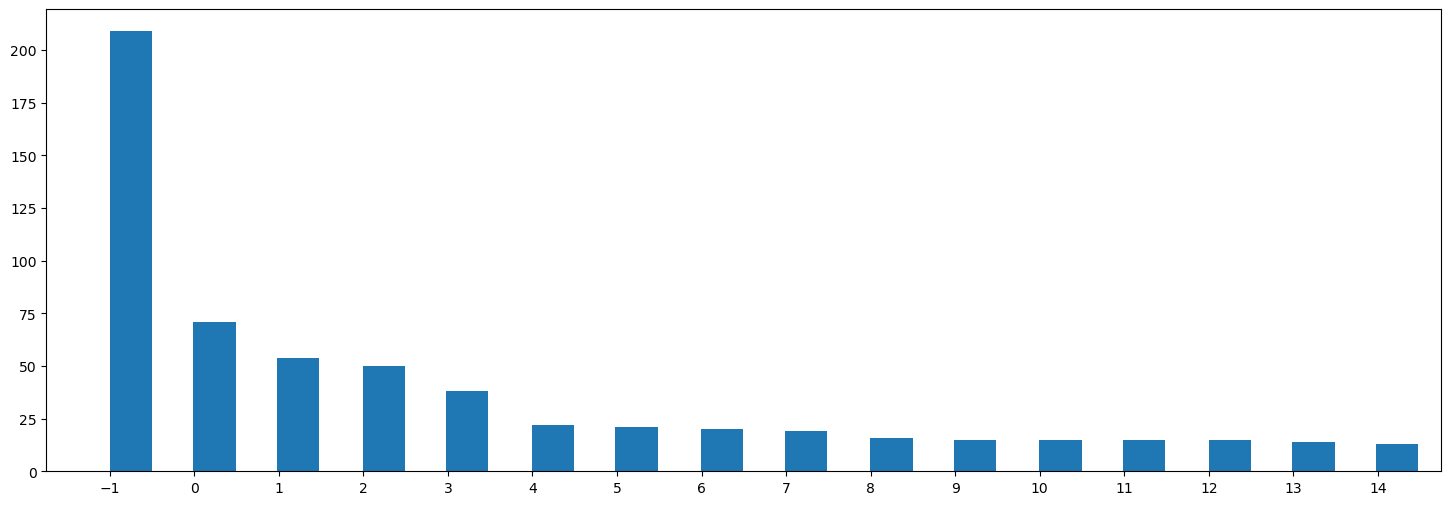
-1 is reserved for outliers that do not initially belong to a cluster.
Statement Distribution
Statement Distribution after outlier reassignment
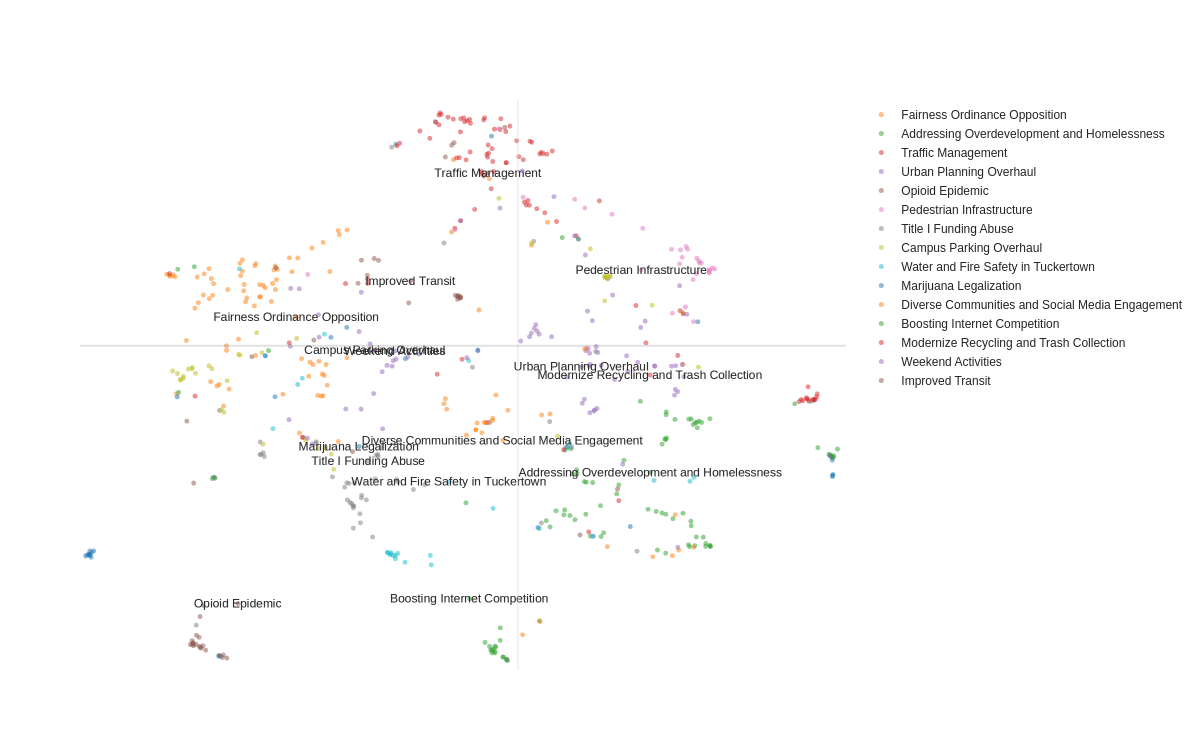
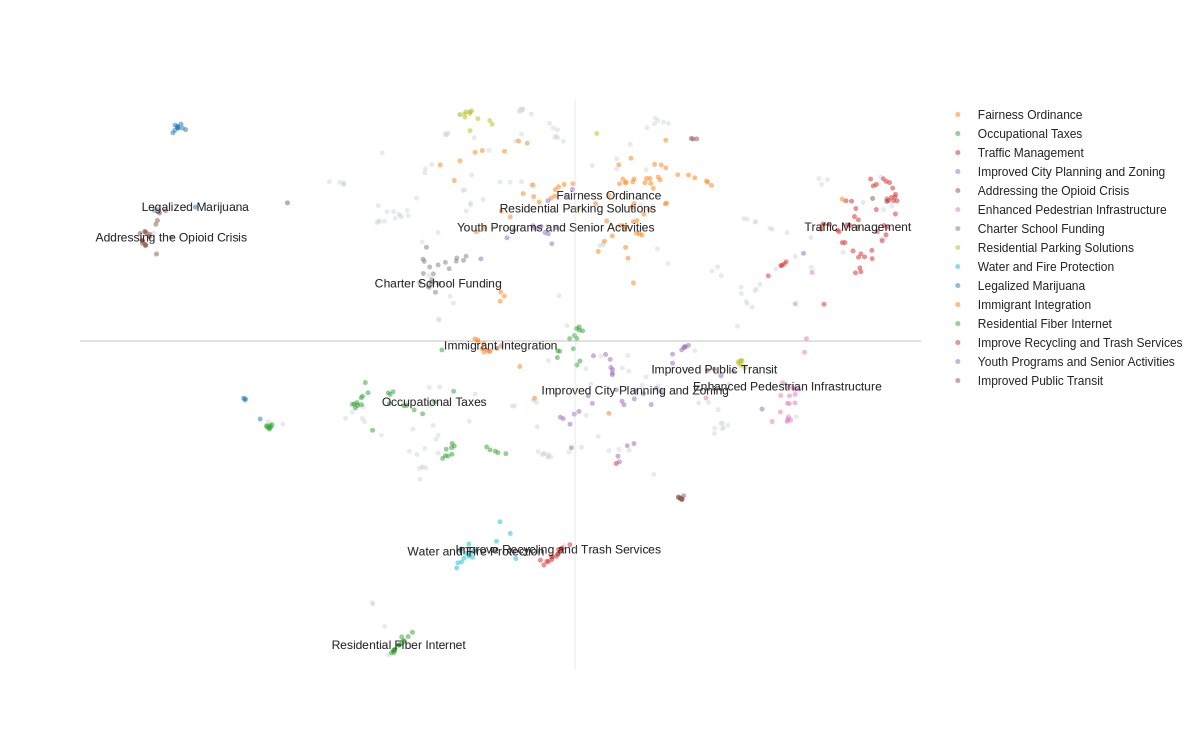
Hierarchical Topic Structure
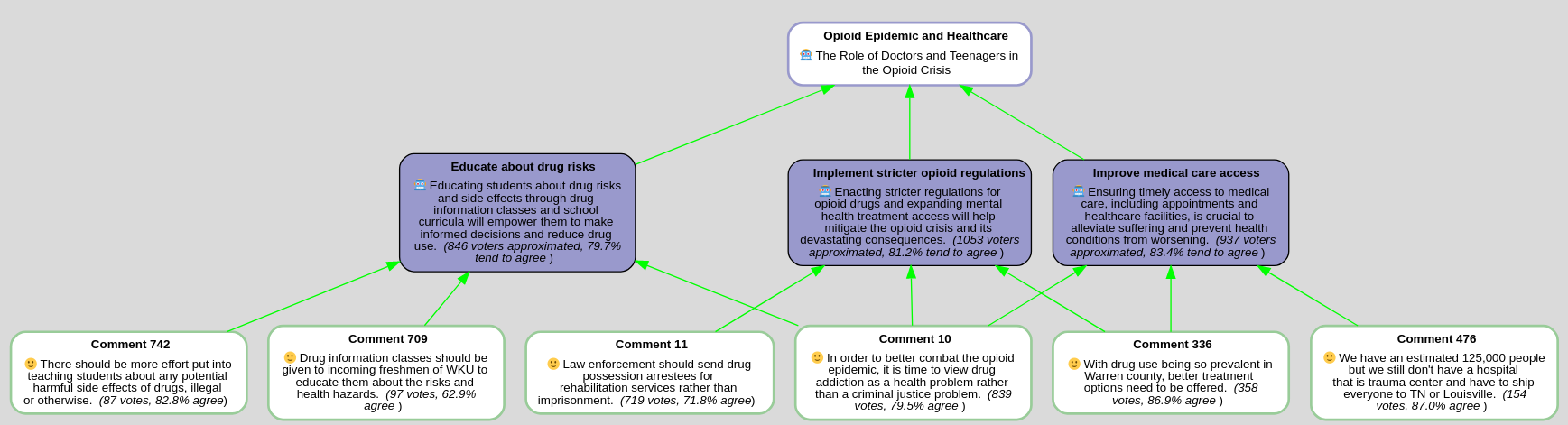
Argument Generation and Scoring
Opioid Epidemic and Healthcare
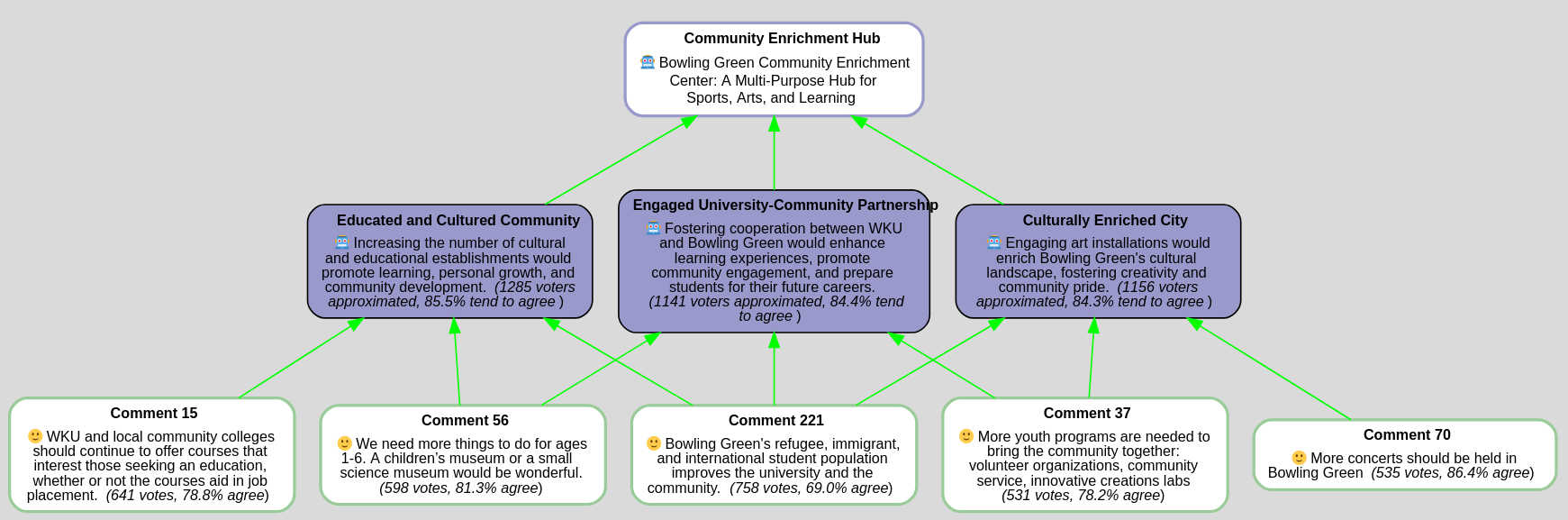
Argument Generation and Scoring
Community Enrichment
Comment Moderation
flowchart LR subgraph Metrics Accuracy Precision FalsePositiveRate UnsureRate end subgraph Tasks Classification ---> Accuracy & Precision & FalsePositiveRate & UnsureRate Classification[Classification: Spam Detection] end subgraph Variables TargetLabels[Target Labels] TargetLabels --> Classification %% TargetLabels --> ThreeClass[ACCEPT, UNSURE, REJECT] %% TargetLabels --> SevenClass[ACCEPT, UNSURE, \nSPAM, IRRELEVANT, \nUNPROFESSIONAL, SCOPE, COMPLEX] %% ThreeClass & SevenClass --> Classification ReasoningTechnique[Reasoning Technique] --> Classification Examples[Use of Examples] --> Classification end