Using LLMs to Structure and Visualize Policy Discourse
Sunday, August 4, 2024
gIBIS
- Networked decision support system (J. Conklin and Begeman 1988)
- Structured conversation using
- Issues
- Positions
- Arguments
- Helped identify underlying assumptions
- Promoted divergent and convergent thinking
- Limited by structure, learning curve, scalability
- Provided the basis for several other tools
Polis
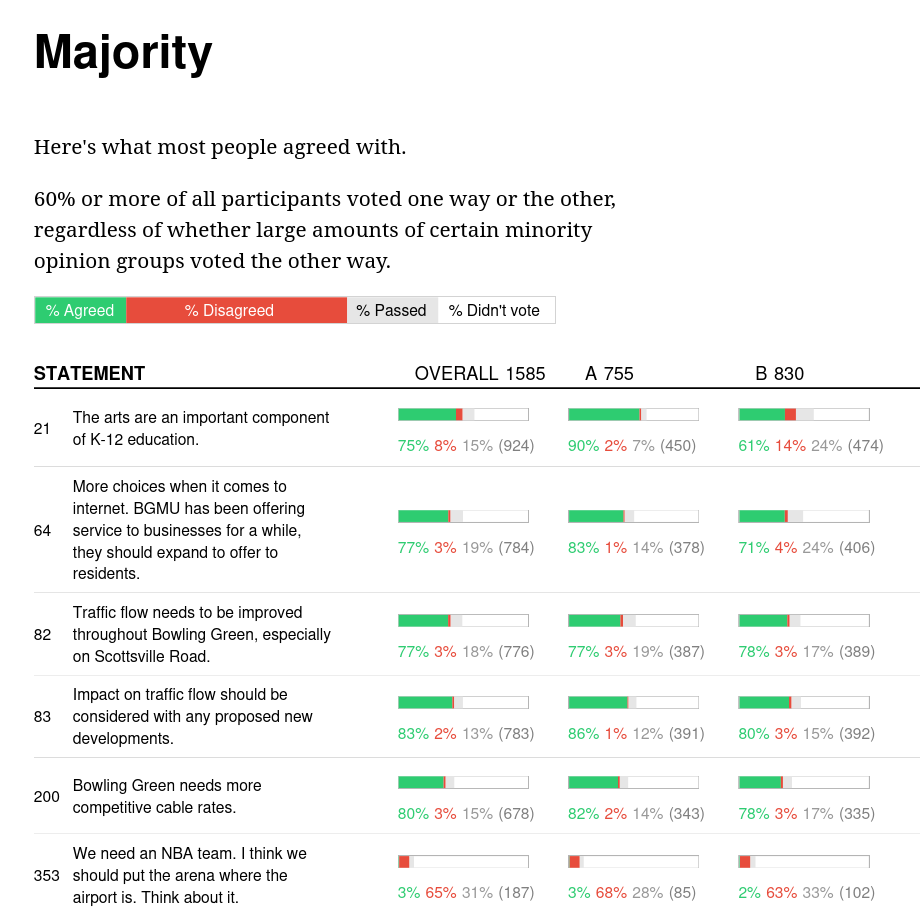
- “Real-time system for gathering, analyzing and understanding” public opinion (Small 2021)
- Developed as an open source platform for public discourse
- Published several case studies
- Participants post short messages and vote on others
- Polis algorithm ensures exposure to diverse opinions
- \(\vec{comments} \times \vec{votes} =\) opinion matrix
- fed into statistical models
- understand where people agree or disagree
Text Generation
- Models Considered
- Guidance
- Python-based framework developed by Microsoft Research
- Constrain generation using regular expressions, context-free grammars
- Interleave control and generation seamlessly
lm += f"""\
The following is a character profile for an RPG game in JSON format.
```json
{{
"id": "{id}",
"description": "{description}",
"name": "{gen('name', stop='"')}",
"age": {gen('age', regex='[0-9]+', stop=',')},
"armor": "{select(options=['leather', 'chainmail', 'plate'], name='armor')}",
"weapon": "{select(options=valid_weapons, name='weapon')}",
"class": "{gen('class', stop='"')}",
"mantra": "{gen('mantra', stop='"')}",
"strength": {gen('strength', regex='[0-9]+', stop=',')},
"items": ["{gen('item', list_append=True, stop='"')}", "{gen('item', list_append=True, stop='"')}", "{gen('item', list_append=True, stop='"')}"]
}}```"""
Topic Modeling
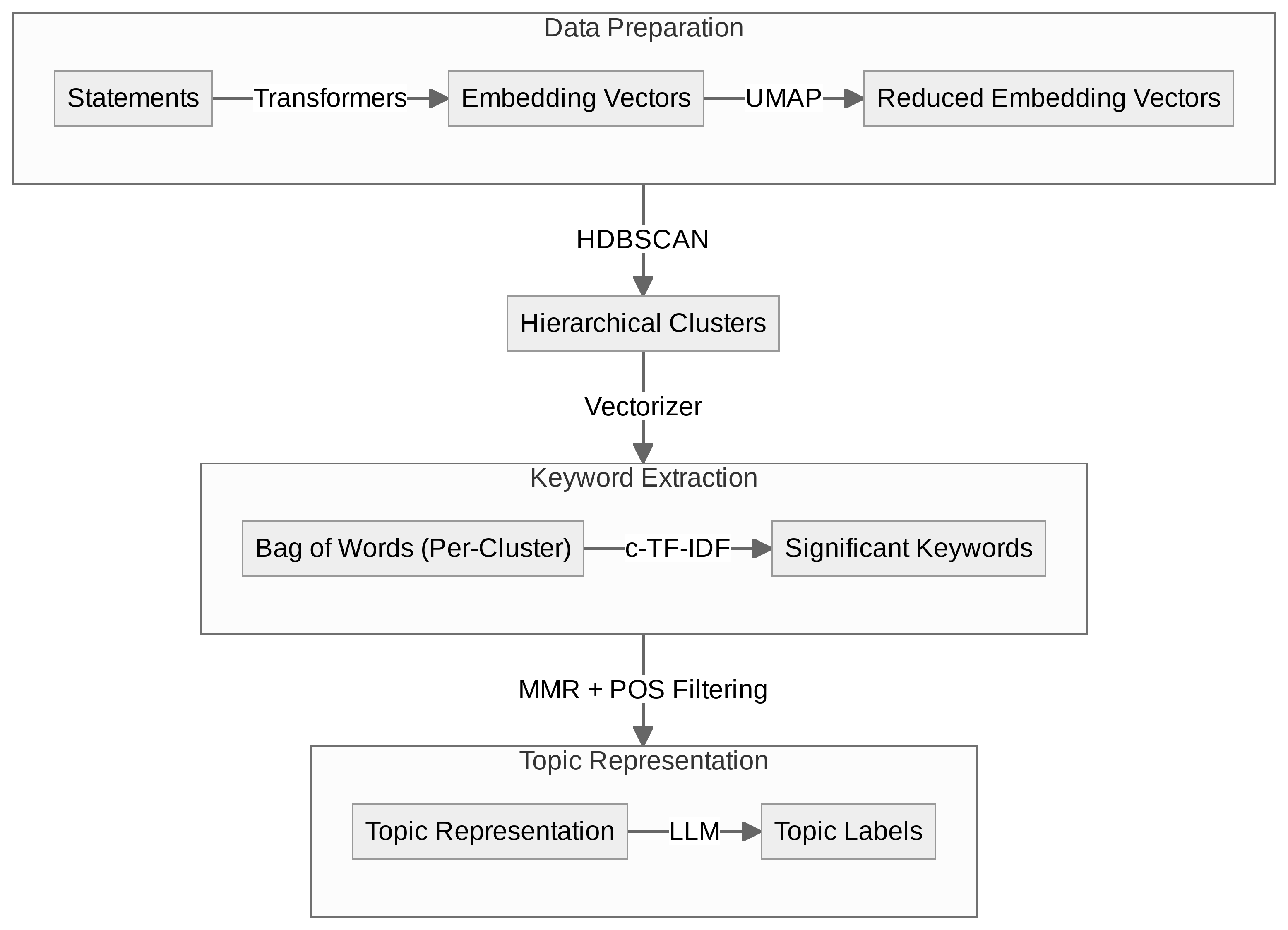
Topic Outlier Assignment
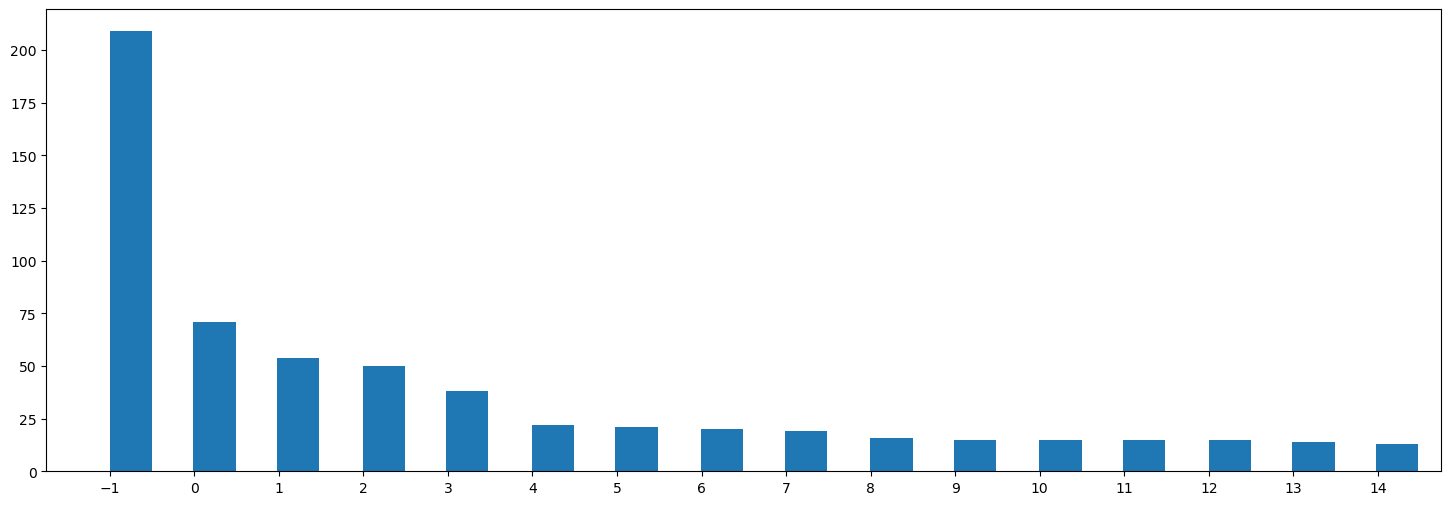
-1 is reserved for outliers that do not initially belong to a cluster.
Statement Distribution
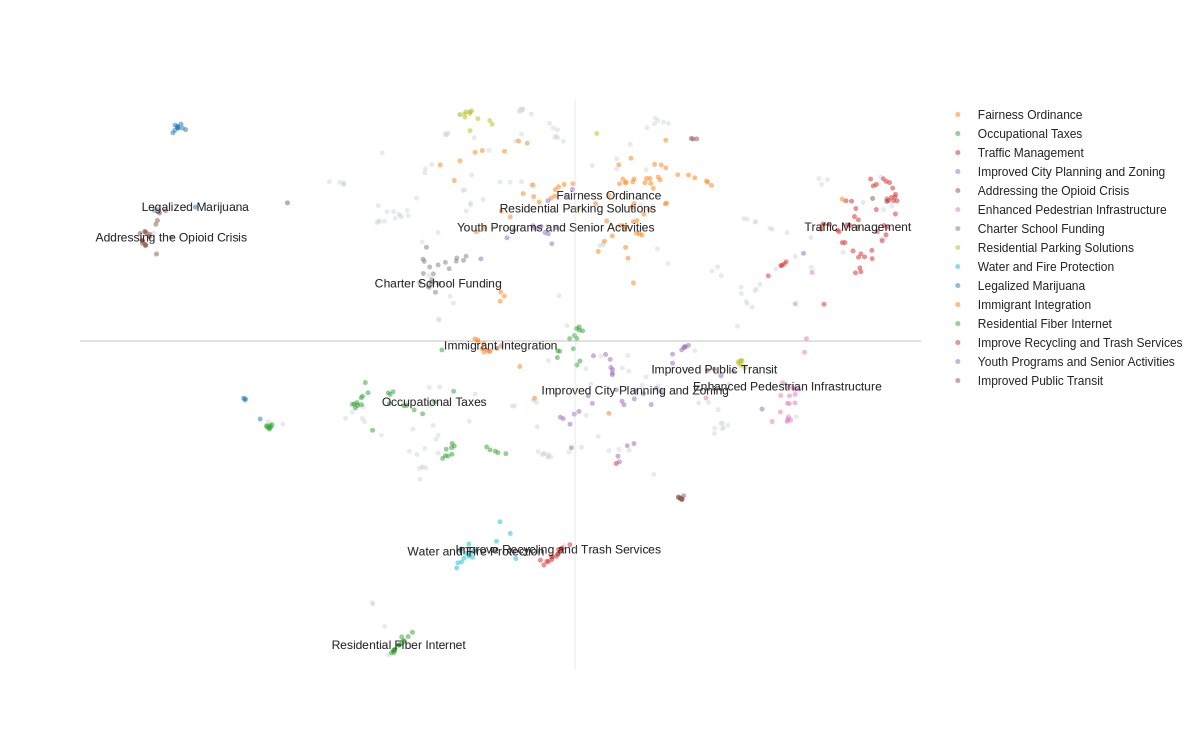
Statement Distribution after outlier reassignment
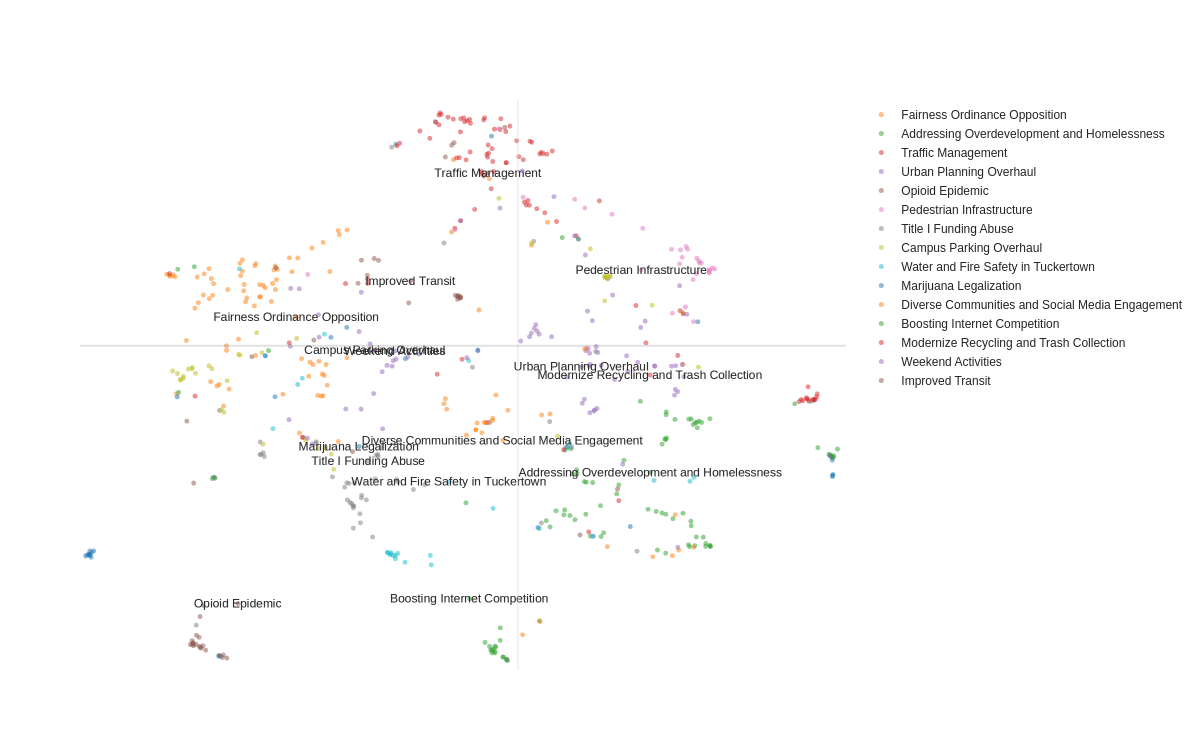
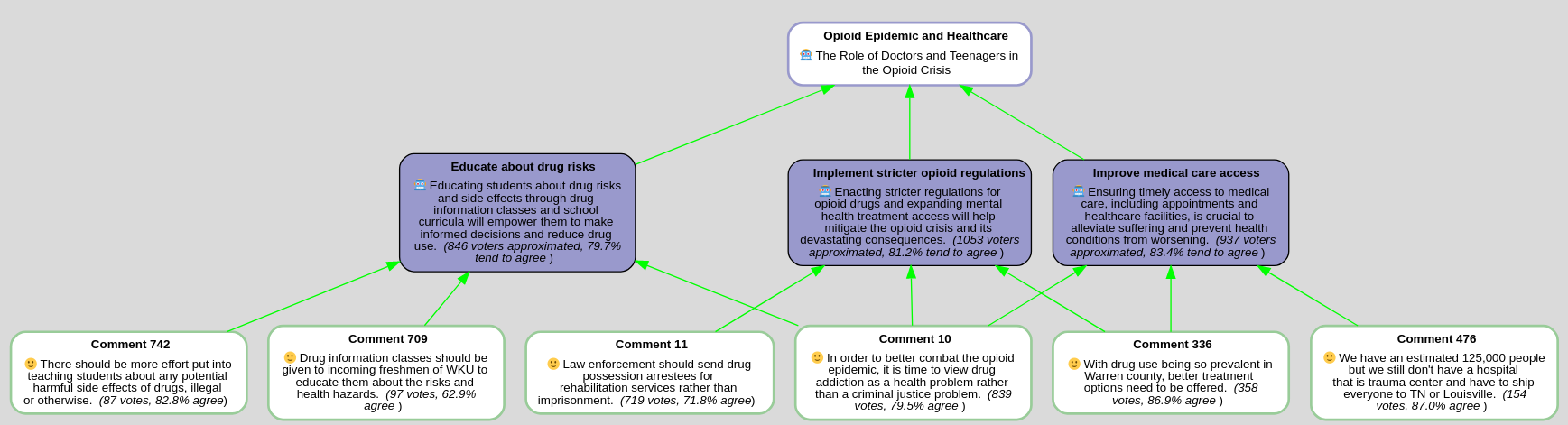
Insight Generation
- Actionable insights that urge for specific actions to address issues
- Problems and solutions proposed by participants
- LLM synthesizes insights from comments within each topic
- Advocate for specific insights urging actions to address issues
- Filter these insights to derive actionable items

Insight Scoring
- Goal: Quantify acceptance of each generated insight
- Task: Identify comments that support each insight
- Count the individuals that voted positively on supporting comments
- Calculate an “acceptance” factor to indicate the degree of consensus
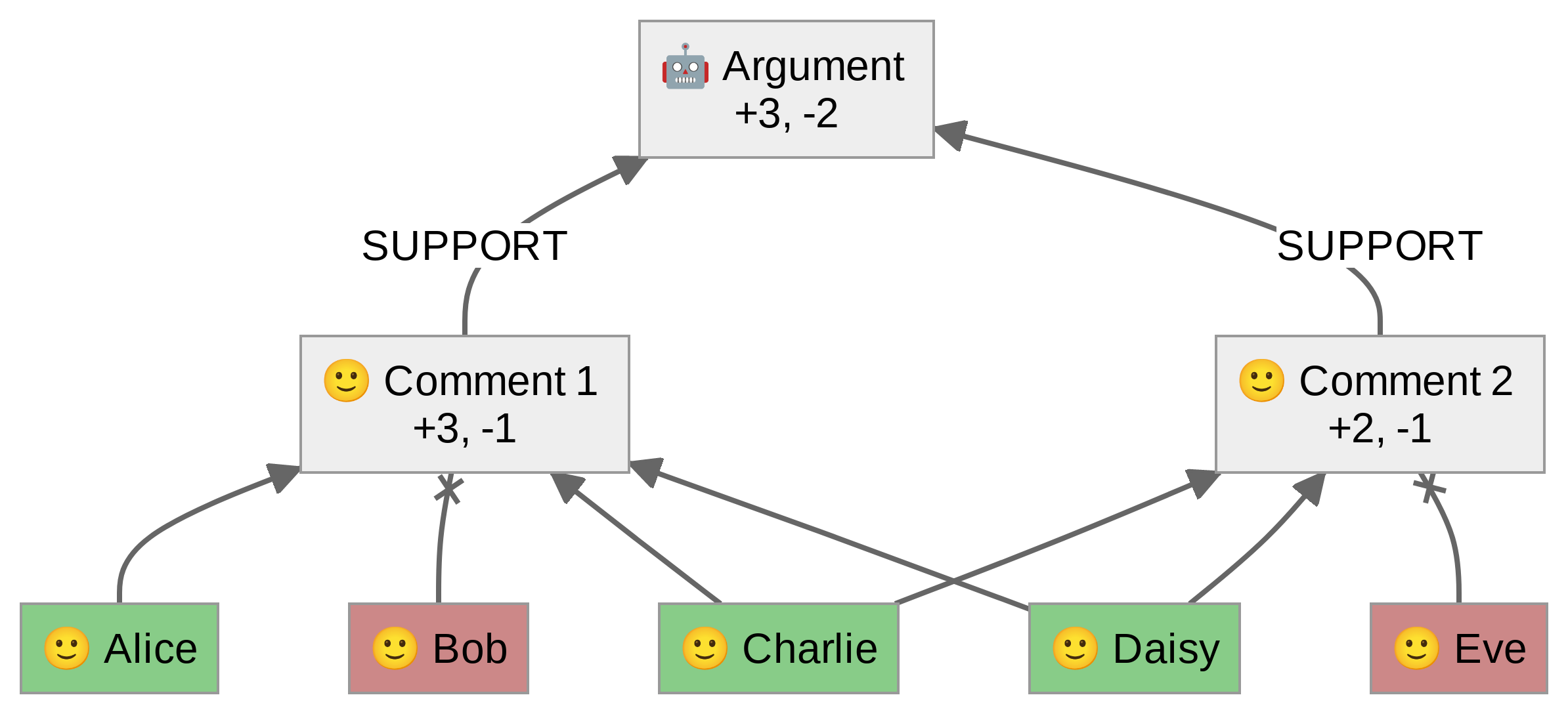
Argument Generation and Scoring
Opioid Epidemic and Healthcare
Argument Generation and Scoring
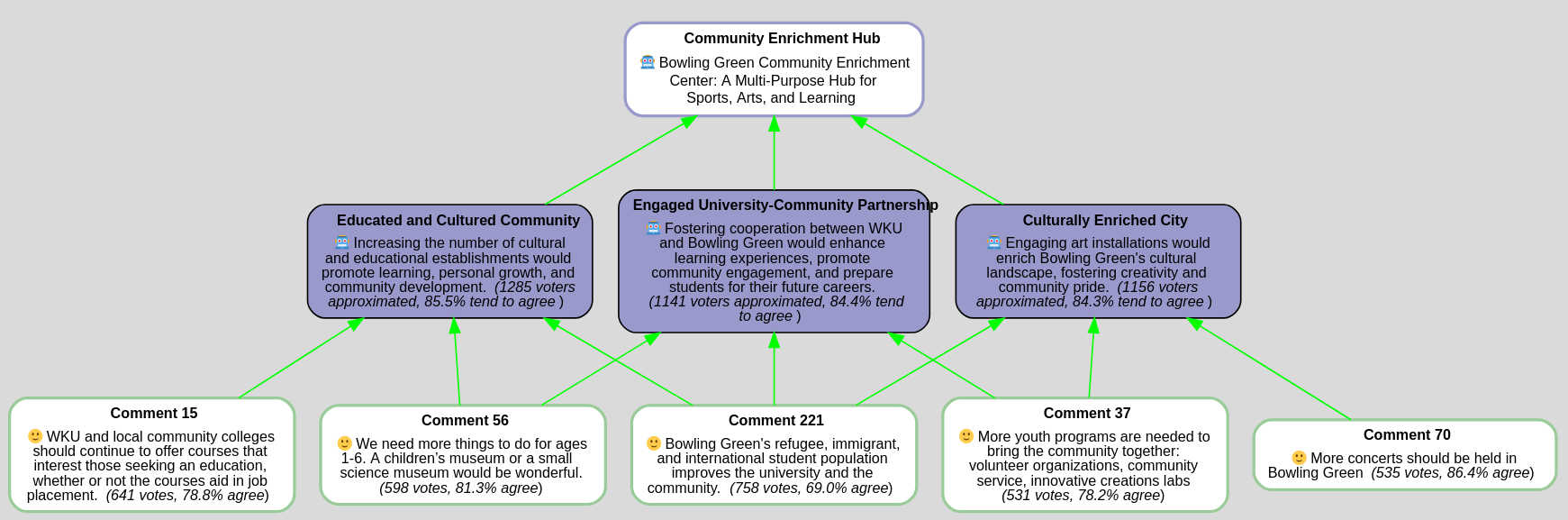
Community Enrichment